


So, you want to be a data scientist?
The glamour, the glory, the drudgery

Data science is simply puffery for applied statistics, which is avoided because statistics is a scary term. Whatever you call it, however, it starts with data.
Data, of whatever underlying quality, arrives at the desk of the analyst in varying states of disrepair and is usually better suited to printing out and reading than to calculation.
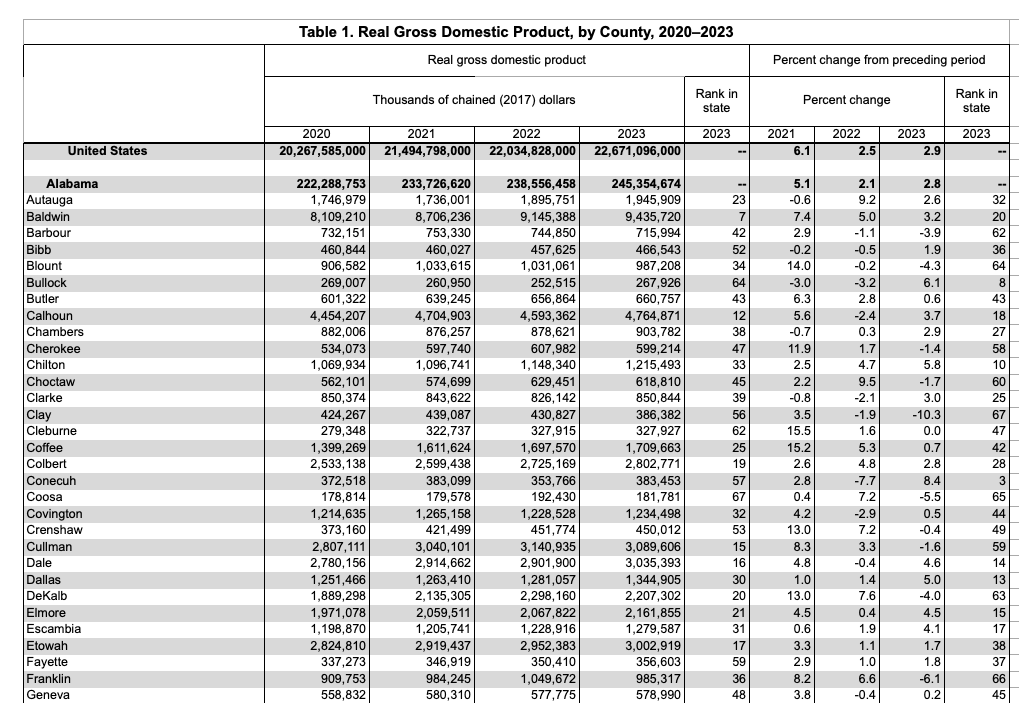
Here’s what I had to do before I could start working on it.
Download the spreadsheet
Open it in Excel
Remove rows 1-5
Use row six to create column headers—label Column A as "county" and Column E as "GDP" with the other columns as "drop"
Select Column E and format it as a number without commas
Export to CSV to the
objdirectory. By convention, we use thedatadirectory for data that is received from others and theobjdirectory for data that is created by the scripts.
This allows the file to be imported with just the two fields of interest, the location and the dollar value. Commas were removed because 1,234,567 isn’t something with you it’s possible to add, subtract, multiply or divide, for which 1234567 is required. They both signify the same quantity, but ones a word and the other is a number.
That wasn’t the end of it, of course. Notice how there’s no field that tells which state a county is located in. For that you have to read up to a row that gives the total for the state. If you think about the printed page mindset, it would look poorly organized if every row repeated the current state. To fix that, I applied a script.
# SPDX-License-Identifier: MIT
"""
GDP Database Creation Module
This module creates and populates a PostgreSQL database table with GDP data for all states,
with special handling for New England states. It processes county-level GDP data and includes
Connecticut planning region GDP data.
# Dependencies
- Census: Custom package for Census data processing
- CSV: File I/O for CSV files
- DataFrames: Data manipulation and analysis
- LibPQ: PostgreSQL database connectivity
# Files Used
- Input:
- obj/state_and_county_gdp.csv: County-level GDP data for all states
- obj/ct_gdp.csv: Connecticut planning region GDP data
- Output:
- obj/ct_gdp.csv: New England GDP data
- PostgreSQL table: gdp
"""
using Census
using CSV
using DataFrames
using LibPQ
"""
create_gdp_database()
Create and populate a PostgreSQL database table with GDP data for all states and territories.
# Processing Steps
1. Reads and processes county-level GDP data
2. Handles special case for New England states
3. Incorporates Connecticut planning region GDP data
4. Creates PostgreSQL table with proper indices
5. Populates table with processed data
# Database Schema
- Table: gdp
- county: VARCHAR(100), part of primary key
- gdp: NUMERIC(20, 2), GDP value in thousands
- state: VARCHAR(50), part of primary key
- is_county: BOOLEAN, indicates if the record is a county or state
- Indices:
- Primary key on (county, state)
- Secondary index on state
# Notes
- GDP values are in thousands of dollars in source data
- Special handling for Richmond City/County disambiguation in Virginia
- Connecticut has separate processing for regional planning areas
- Records are classified as counties or states using VALID_STATE_CODES
"""
function create_gdp_database()
# Get project root directory
project_root = dirname(dirname(@__FILE__))
# Read and process main GDP data
gdp = CSV.read(joinpath(project_root, "obj", "state_and_county_gdp.csv"), DataFrame)
gdp = select(gdp, :county, :GDP)
# remove footnotes
deleteat!(gdp, [3217, 3218])
# Add is_county flag and handle state records
gdp.is_county = trues(nrow(gdp))
gdp.state = fill("", nrow(gdp))
for i in 1:nrow(gdp)
if gdp.county[i] in keys(Census.VALID_STATE_CODES)
gdp.is_county[i] = false
state_code = Census.VALID_STATE_CODES[gdp.county[i]]
gdp.state[i] = gdp.county[i]
gdp.county[i] = state_code
end
end
include(joinpath(project_root, "src", "fill_state.jl"))
rename!(gdp, [:locale, :gdp, :is_county, :state])
fill_state!(gdp)
gdp = gdp[gdp.is_county, :]
gdp = gdp[:, [1, 2, 4]]
gdp.gdp = gdp.gdp .* 1e3
# Add Connecticut planning region data
ct_gdp = subset(gdp, :state => ByRow(x -> x == "CT"))
deleteat!(ct_gdp, nrow(ct_gdp)) # Remove empty state row
ct_gdp = ct_gdp[:, [1, 2]]
rename!(ct_gdp, [:county, :gdp])
ct_gdp.state = fill("Connecticut", nrow(ct_gdp))
ct_gdp.is_county = trues(nrow(ct_gdp)) # Connecticut regions are treated as counties
# Process remaining states
gdp = filter(:state => x -> x != "CT",gdp)
# Rename Richmond City (largest GDP Richmond jurisdiction)
richmond_mask = (gdp.locale .== "Richmond") .& (gdp.gdp .> 20_000_000_000)
gdp.county[richmond_mask] .= "Richmond City"
gdp = gdp[:, [1,2]]
rename!(gdp, [:county, :gdp])
ct_gdp = ct_gdp[:, [1, 2]]
gdp = vcat(gdp, ct_gdp)
# Create and populate database
# omitted
end
In the course of taking care of associating states with counties, a couple of small problems came up and one bigger problem.
At the end of the data there were some footnotes to delete and Virginia had two subdivisions named “Richmond.” Simple enough. More challenging was the discovery that the data for Connecticut uses its eight obsolete counties, which have been replace in the Census data by nine county equivalent “regions.” The Bureau of Economic Analysis hasn’t caught up yet.
To fix that problem required a crosswalk. Connecticut's transition from eight historical counties to nine planning regions (or Councils of Governments, COGs) as county-equivalents for Census purposes does not follow a one-to-one correspondence. The new planning regions often overlap with the boundaries of the old counties but also divide some counties into multiple regions. Here is a general outline of how the eight counties correspond to the nine planning regions:
Fairfield County: Split into two planning regions:
Western Connecticut COG (WestCOG)
Greater Bridgeport COG
Hartford County: Primarily aligns with the Capitol Region COG (CRCOG), though parts may overlap with other regions.
Litchfield County: Corresponds to the Northwest Hills COG (NHCOG).
Middlesex County: Divided between:
Lower Connecticut River Valley COG (RiverCOG)
Naugatuck Valley COG (NVCOG)
New Haven County: Mostly aligns with the South Central Regional COG (SCRCOG), though parts also fall under NVCOG.
New London County: Corresponds to the Southeastern Connecticut COG (SECCOG).
Tolland County: Primarily falls under the Capitol Region COG (CRCOG).
Windham County: Corresponds to the Northeastern Connecticut COG (NECCOG).
The Connecticut Crosswalk File apportions the state's county-level population to the Connecticut planning regions and is used to create the ct_gdp.csv file in the create_gdp_database.jl script to apportion GDP proportionally to population.
With that accomplished, I could then go on to do what I set out, which was to find the gross domestic product of the nation states that I am in the process of splitting off from the United States. I’ve done an initial cut respecting current state lines and am now working at the county level to adjust boundaries.
All of this is fairly pedestrian but reflects the common experience in the field, which is that your data sources are seldom prepared with your convenience in mind.
Indeed. I can attest to lots of Python code for cleaning up dirty data.
I don't use/have MS Office, so I usually jump directly to a CSV or TAB file, if available. I've even had to edit my "csvfile" class to handle the broken CSV generated by WordPress (they don't handle fields with embedded double-quotes at all according to RFC 4180).